Many of you will by now have heard of ChatGPT, the Large Language Model (LLM), developed by OpenAI. It’s an interactive and incredibly powerful Machine Learning (ML) tool that can generate detailed responses across a wide range of topics.
ChatGPT was trained on a vast amount of data which allows it to generate human-like responses by predicting the next word in a sentence. While ChatGPT was coded with good intentions, we’d like to explore how the tool could be problematic from a cybersecurity standpoint.
What are the fundamental uses of ChatGPT?
ChatGPT-4 is the fourth iteration of the Generative Pre-trained Transformer (GPT) language that is still in the developmental phase. It’s said to supersede GPT-3 which included around 175 billion parameters, making it the world’s largest Artificial Intelligence (AI) model.
Both models exude an impressive grasp of natural language processing and at the time of writing, can generate human-styled text, poetry and stories as well as complete and functional lines of software code. GPT-4 is expected to be able to write complex essays and articles as well as compose music and art. While all of these developmental tasks are impressive, the GPT models are at risk of being used for more mischievous activities.
How can AI negatively affect the cybersecurity landscape?
While the GPT models aren’t inherently a risk for cybersecurity, the way in which they can be used can be problematic. Since its publication in January 2023, it became the fastest growing app to reach 100 million users within two months.
There is some discrepancy in the discussion around whether later GPT models will create malware and ransomware, or any new cyber threats, but regardless of that outcome, the LLM is being used to speed up mundane tasks and augment other coding structures that are being used by bad actors. Using AI to script the baseline code means that the hacker would be able to develop multiple coding structures at a time leading to an increase in the number of cyberattacks.
The availability of ChatGPT creating code also effectively lowers the bar for other aspiring cybercriminals, who perhaps don’t possess the same caliber of coding skills as those currently on the Internet. And if that wasn’t bad enough, the advanced understanding of LLM also allows for automated vulnerability discovery – scanning code to identify potential weaknesses.
Aside from the code issues, there is also the privacy and copyright argument, due to where the LLM sources its information. More on this later.
How reliable are ChatGPT’s responses?
At least so far as the current models are concerned, ChatGPT fails to mimic or employ critical thinking and thus, its accuracy can easily be brought into question, particularly since its knowledge base is still limited to anything that happened before 2021. However, with that in mind, we wanted to give you an example of how ChatGPT works, where you may not be able to distinguish whether it’s human- or AI-written.
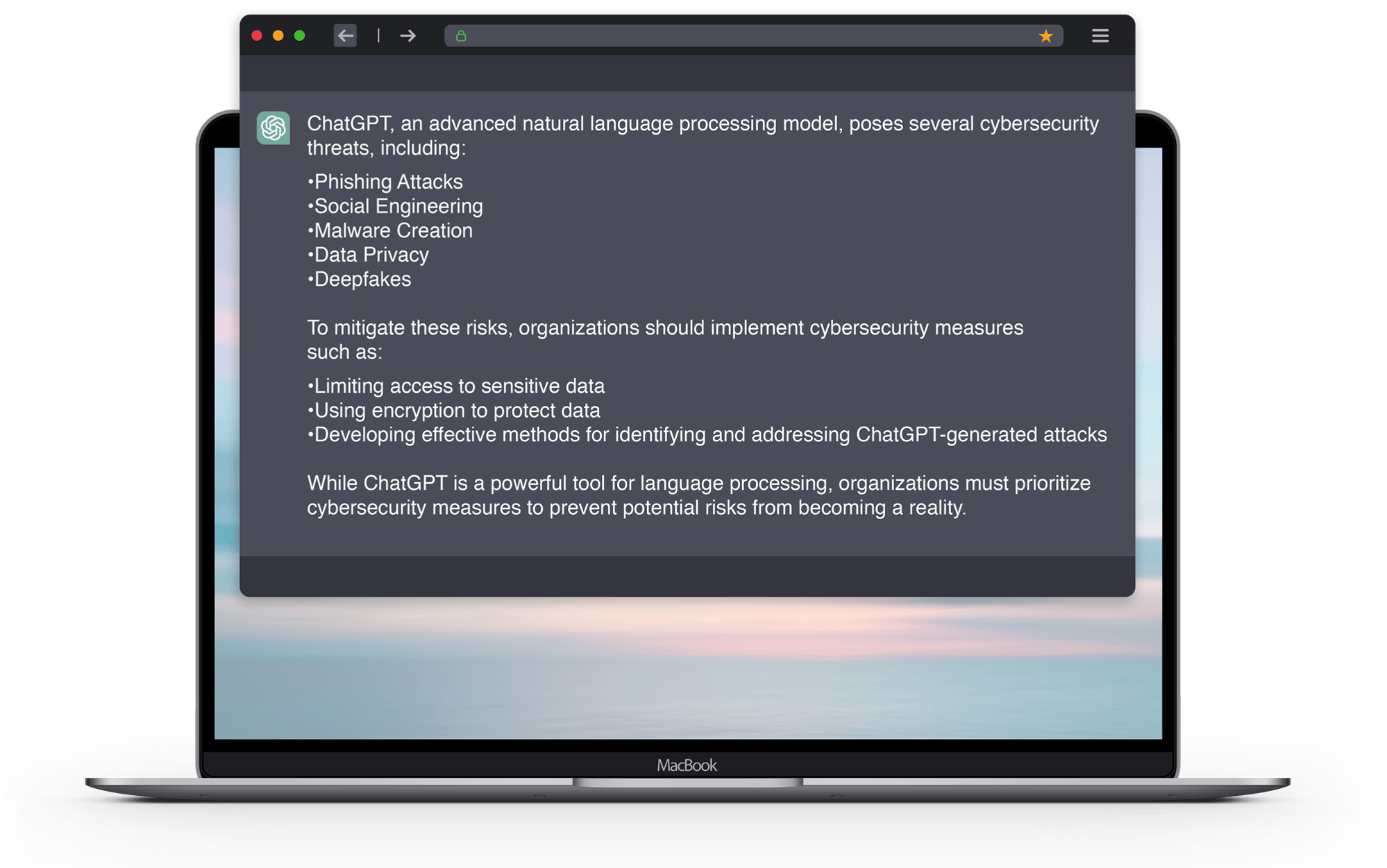
We asked it through a series of prompts (called Prompt Engineering) to generate a response to the following statement:
“Write in 500 words – including a bullet point list of the top 5 reasons – why ChatGPT could be problematic for cybersecurity?”
We chased it up with summarizing prompts to reduce the word count. These were written casually as if we were talking to a colleague, and it answered with:
In this instance, the accuracy of the content provided in its answer is reasonable, as multiple external sources can substantiate its claims.
What other cybersecurity steps can be taken to regulate ChatGPT’s capability?
In addition to the suggestions made by ChatGPT, there are several other methods that have been in development for the recognition of text to help against impersonation, plagiarism and cheating. Examples of this include Turnitin’s AI detection for educational institutes and OpenAI’s classifier.
Yet these detectors only really look at the aftereffects of the problem, rather than mitigating the risks in the first place. The AI function needs to be submitted to much higher scrutiny from a regulatory perspective as the collection of data and unregulated usage can prove to be particularly devastating.
It’s these necessary regulations that need to be brought to the forefront of the AI/ML technological developments, to help in securing both the personal identifiable information and reducing the rate at which malicious code is developed.
What could AI-related regulations look like?
While there aren’t currently any regulations that define the boundaries for what is deemed acceptable for ChatGPT and other AI/ML systems, having a look at the science fiction by author Isaac Asimov lends thought to the potential for a short set of overarching rules. Big Think’s article touches on Asimov’s Three Laws of Robotics and makes a compelling argument to include a fourth – that an AI system should identify itself.
Given the unrest in the cybersecurity space at the moment, setting limitations on the capabilities and permissions, as well as how easily they can be distinguished, could be the place to start.
At the end of the day, AI tools should look to enhance for the better, rather than cause damage to intellectual property or sensitive information.
Interested in keeping up to date with cybersecurity developments?
The world of AI and tech is rapidly evolving with changes every week. The cybersecurity field is adapting at arguably the same rate. Subscribe to our blog to keep up to date with the latest developments.