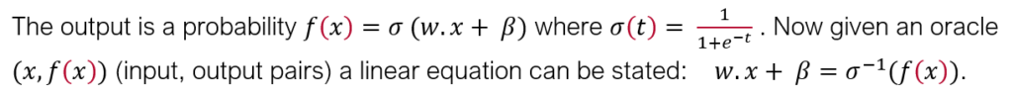What would privacy-preserving ML look like? (Part 2)
In my previous post, we covered why protecting the privacy (and confidentiality) of data is so paramount and how ML-based systems amplify privacy concerns due to the sheer amount of data and the processing power available. We also discussed why the naive approach for ensuring privacy i.e., removal of identifying information from the data, isn’t enough by citing some examples from the real world (Netflix and Triton Trojan examples).
A more recent example of how users’ personal and sensitive data may be breached is how the locations of Ring cameras were leaked when reporters from Gizmodo investigated the privacy guarantees that Ring promises to its users. Even though Ring uses a combination of AES encryption and Transport Layer Security (TLS) to secure data between Ring devices and apps, the coordinates tied to each video post remain visible to any sufficiently technical user [1].
I also discussed some attack contexts and scenarios (e.g., the class membership inference attack) and promised to detail a specific attack called the model stealing attack also referred to as the model extraction attack.
Model Stealing Attacks
This type of attack assumes the ability to query the model but otherwise no other access to the training data nor to the model internals is permitted (this is the so called blackbox context). In this case, the attacker actively probes a learning method and analyzes the returned output to reconstruct the underlying learning model [2]. This is an attack that affects the confidentiality of the model but also potentially the privacy of the training data (similarly to the membership inference attack).
For a concrete example of how this attack works in practice, let’s consider an example using Binary Logistic Regression (LR). An LR model performs binary classification by estimating the probability of a binary response, based on a number of independent features.
How difficult is it for an attacker to find out values for w and via black box queries? Turns out the answer is not that difficult at all. As we will detail below, the attacker queries n+1 random points and solves a linear system of n+1 equations.
Example of a Model Stealing Attack
Below is some data under columns X1 and X2 (independent variables) and their classifications under the column Y (the dependent variable). Here the dimension of the inputs n is 2 so solving a linear system of 3 equations should be enough to reveal the values w and resulting in the model being stolen.
Using an online LR calculator, at confidence level 95%, we obtain the following model, where WX + = 13.3080.X1 − 12.5834.X2 − 24.8685 (where W, X and are vectors).
As a blackbox model, all an attacker can assume is the shape of a binary LR model: f (X1, X2) = W1.X1 + W2.X2 + . We can steal the model if we can find out values for W1, W2 and . We do this by issuing a number of queries (hopefully only 3 queries but as we will see we may need to do more) and setting up a system of linear equations in 3 unknowns and then solving the linear equations.
Below, we have issued 4 queries: for each X1 and X2, get the result f (X1, X2). Notice that we cannot use the value of ‘1’ for f (X1, X2) for the 3rd query as we will see later so we issue one more (line 4). Now we solve for W and in WX + .
Knowing the f (X1, X2) values which are the sigmoid function values for the model, we set up the following matrices, where the rows in matrix A are the X1, X2 values (plus a ‘1’ so our matrix multiplication works out), column matrix X is simply the unknowns (W1, W2, ) and column matrix B is the values the model returned for each query i.e., f (X1, X2):
Solving for column matrix X, with this Python code snippet:
We get the values for (W1, W2, ). Comparing with the model we had WX + = 13.3080.X1 − 12.5834.X2 − 24.8685. We see that we have recovered the model parameters and basically extracted (stolen) the model.
How about other logistic models?
For Multinomial LR and Multilayer Perceptrons (DNNs), an attacker needs to solve a corresponding non-linear equation which is admittedly harder, but by no means impossible. For decision trees, an attacker could use a corresponding path-finding algorithm [3].
Let’s now discuss a specific approach to privacy-preserving ML, namely Federated learning (FL), where blackbox attacks such as model stealing attacks will not be of primary concern. As we will discover, FL is however not a panacea and other types of attacks and vulnerabilities are possible.
Privacy-preserving ML: Federated learning
Federated learning (FL) is distributed learning where model training no longer takes place at a central cloud server. Model training instead is distributed among many client devices which use local data to train a local model and only send their model parameter updates. The server uses the individual updates from clients and aggregates them to build a shared model. Having kept local data on the devices and not sharing them with a server helps allay privacy concerns to a large degree. In short, bring “code to data” instead of “data to code”.
Besides privacy gains, FL has additional advantages such as reduction in network communication cost and offering a better overall model that is both global and personalized to the individual client. Pushing some of the computation needed to train a large model to the edge client devices is also a definite plus for FL.
FL is however not without its challenges. For example, even though there are clear network communication cost savings in a FL setting due to reduction of what is actually communicated over the network, the sheer number of devices that may participate in training could more than make up for any cost savings gained in only sending model updates. Researchers are actively looking to optimize the total number of communication rounds, and also further reduce the size of transmitted messages at each round [4].
What about new vulnerabilities?
Model poisoning attacks: the goal of an attacker is to get the model to misclassify a set of chosen inputs with high confidence i.e., poison the global shared model in a targeted manner. This is also a kind of evasion attack or at least could lead to an evasion attack. Model poising attack is the counterpart of data poisoning attacks for non-FL contexts.
Membership inference attack by a malicious participant (or malicious aggregator/server): What can be inferred about the local data used for training the local model? Given an exact data point, was it used to train the model for a specific client?
The malicious participant in this scenario knowing his own local updates and having access to snapshots of the shared model, may find out another participant’s local update [5].
So model updates in an FL context still need to be protected via differential privacy or secure multiparty computation. However as always, a balancing act is often needed as these approaches often provide privacy at the cost of reduced model performance or system efficiency [4].
Conclusion
In this two-part blog post, we highlighted the importance of data privacy, some examples of how and when privacy could be breached, and why is preserving privacy is hard specially in the age of AI/ML where vast amounts of data and processing power are available.
On the more positive side, we covered some advances in privacy-preserving ML, specifically FL, including its advantages and disadvantages, while hammering the point on why privacy (and more generally security), is a balancing act. This is especially true given the increasing number of devices connected to the internet in some way. According to International Data Corporation (IDC) “there will be 41.6 billion connected IoT devices, or “things,” generating 79.4 zettabytes (ZB) of data in 2025.”
[2] Lowd, D., and Meek, C. Adversarial learning. In Proc. of ACM SIGKDD Conference on Knowledge Discovery in Data Mining (KDD) (2005), pp. 641–647.
[3] Tramèr, F., Zhang, F., Juels, A., Reiter, M. K., and Ristenpart, T. Stealing machine learning models via prediction apis. In Proc. of USENIX Security Symposium (2016), pp. 601–618.